

Bias in the Bubble: New Research Shows News Filter Algorithms Reinforce Political Biases
Algorithms used to recommend books or movies might help people discover a new favorite author or director, but algorithms used to recommend news and opinion articles can redirect readers in problematic ways.
Researchers at Illinois Institute of Technology looked to see how algorithms recommending news stories can create filter bubbles, exposing readers to stories that skew toward a reader’s preconceived political views. Learning how these algorithms work and how they affect readers is a crucial first step in understanding the consequences that can occur as people are drawn into these bubbles.
This year, Mustafa Bilgic, associate professor of computer science at Illinois Tech, and Matthew Shapiro, professor of political science, published “The Interaction Between Political Typology and Filter Bubbles in News Filter Algorithms.” Additional collaborators included Ping Liu, a Ph.D. candidate in computer science at Illinois Tech; Aron Culotta, an associate professor of computer science at Tulane University; and Illinois Tech alumnus Karthik Shivaram (M.S. CS ’17), now a Ph.D. student in computer science at Tulane. The National Science Foundation’s Division of Information and Intelligent Systems provided funding support.
To conduct their study, the team of researchers gathered and curated a collection of more than 900,000 news articles and opinion essays from 41 sources annotated by topic and partisan lean. A simulation investigated how different algorithmic strategies affect filter bubble formation. Drawing on Pew Research Center studies of political typologies, heterogeneous effects based on the user’s pre-existing preferences were identified.
“If the algorithm shows you only the news that it thinks you are going to like, to maximize its chances that you will click on it, you may not know that these other perspectives and these other news even exist,” says Bilgic, who served as the principal investigator on the project. “And because all of it is done behind the scenes, you probably wouldn’t notice that automated algorithms are filtering and selecting news for you.”
“Social media is designed for maximizing attention of the user so that ads and other marketing tools can be revenue generators,” Shapiro says, “which happens through the filter bubble. It’s about attention, and it’s about keeping that attention. The average individual is going to be most satisfied interacting with people like themselves. What does it mean if people are using social media as much as they are and they’re not engaging with different kinds of people?”
Nine classes of users were simulated based on Pew’s existing political typologies: core conservative, country-first conservative, market-skeptic republicans, new era enterprisers, devout and diverse, bystanders, disaffected democrats, opportunity democrats, and solid liberals. The simulated users were fed articles from 14 different topics to measure the change in diversity of recommendations introduced by the recommendation system, versus what would be expected based solely on the users’ true preferences. The article topics included abortion, the environment, guns, health care, immigration, LGBTQIAA issues, racism, taxes, big tech, trade, impeachment, the United States military, the 2020 election, and welfare.
The algorithm used collaborative filtering, which makes recommendations based on the preferences of people with similar views, and content filtering, which makes recommendations based on the content in the articles.
The types of filtering created by these algorithms were very different. Content-based filters rely on partisan language used in the articles to make recommendations. Collaborative filters make recommendations based on popular articles read by a group that best match a specific reader’s preferences.
“One is looking at how an individual deals with the news itself, while the other is looking at how an individual deals with others who are more or less like them,” Shapiro says. “Both are going to have some sort of bias.”
The study shows content-based recommendations are susceptible to biases based on distinctive partisan language used on a given topic, leading to over-recommendation of the most polarizing topics. Collaborative filtering recommenders, on the other hand, are susceptible to the majority opinion of users, leading to the most popular topics being recommended regardless of user preferences.
The researchers found that users with more extreme views were shown less diverse content and that they had the highest percentage of click rates.
“It’s of course easy for the algorithm to make recommendations and maximize clicks for users with extreme views,” Bilgic says.
Some users have a mix of views. For example, they may have conservative views on taxes, but more liberal views on social issues. In these cases, the recommending algorithms tended to have a homogenizing effect, pulling them in one direction. However, the two different recommenders accomplish this in different ways.
Linguistic overlap between topics tends to mislead content-based filters. For example, “baby” appears in articles on both abortion and health care. A reader might have conservative views on abortion, but liberal views on health care. If they click on abortion articles with a conservative view on abortion, the algorithm will also recommend conservative articles on health care as well, pulling the reader toward more conservative news in general.
Collaborative-based filters create the same result. In this case, if the reader clicks on conservative abortion articles, the algorithm treats the reader as having conservative views and will recommend health care articles that are popular with other readers having conservative views on abortion.
“The algorithm has a hard time separating these topics from each other due to their linguistic and social overlap,” Bilgic says. “That’s why the algorithm is showing you things that are also conservative on health care. That’s the homogenization effect.”
Bilgic says the research group plans to continue this research using two groups of human readers. One group will use the algorithms as is, and the other will be able to input controls on the algorithm based on their political views, as well as the topics they want to read about.
“If we present people more information about how the algorithm is filtering news for them, and give them knobs to adjust the algorithm’s behavior, will people take it more to the extremes or will they read news articles with different views? Will they be able to combat the homogenization effect of the algorithms?” Bilgic says. “That’s what we will study next through user studies.”
From a public policy perspective, Shapiro says there are things that the government could do to help address the problems created by news filter bubbles.
“It would be a long shot to expect the government to do anything about the misinformation,” he says. “What would be most interesting would be the government making it a law that all of the information [on how the algorithms work] be made available to you.”
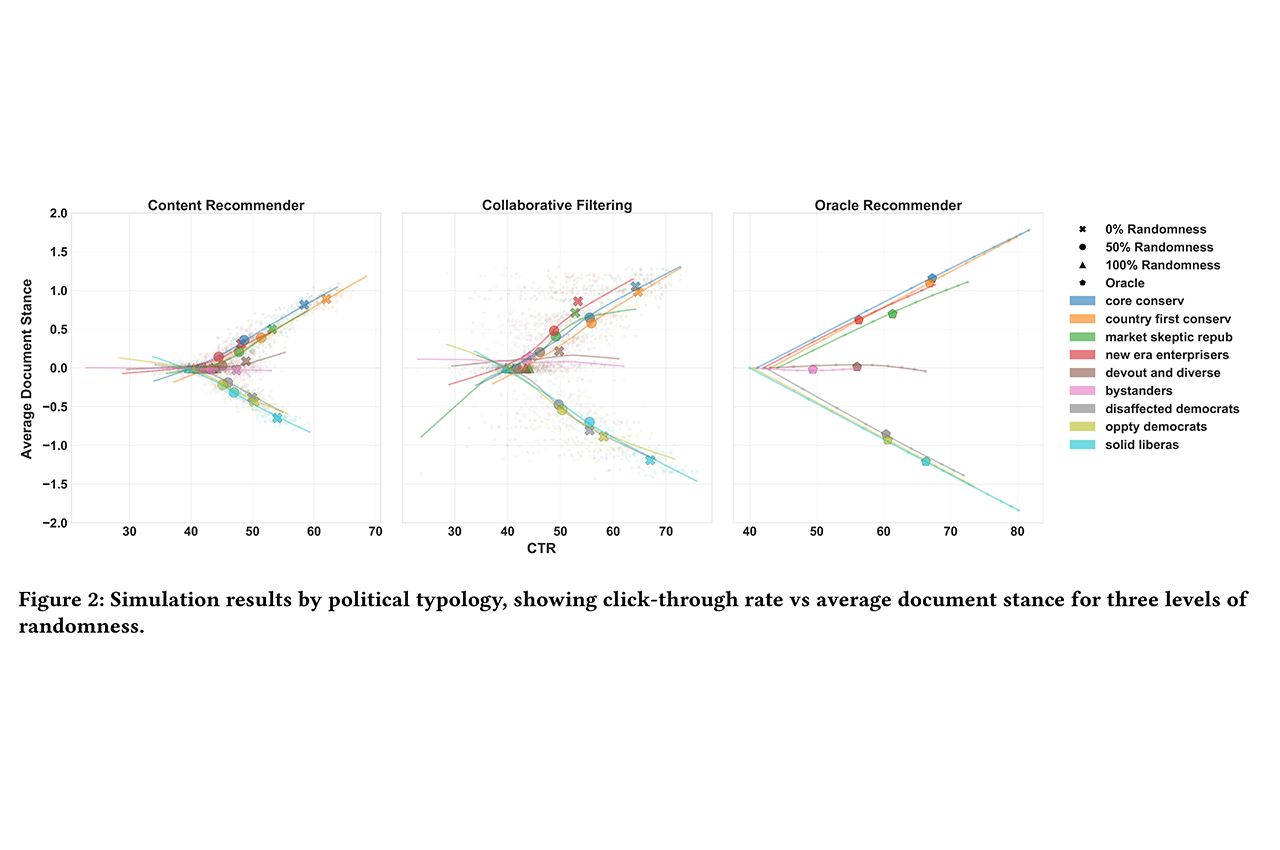
Photo: Simulation results by political typology, showing click-through rate versus average document stance for the three levels of randomness. The types of filtering used were very different. Content-based filters rely on partisan language used in articles to make recommendations, collaborative filters make recommendations based on popular articles read by a group that best matches a specific reader’s preferences, and oracle recommenders sample documents proportional to the user’s probability of liking these documents. Despite these differences, there is a general consistency based on an analysis of the clickthrough rates of different classes of users versus the average document stance more extreme political types have both higher clickthrough rates and higher magnitude document stances, while more moderate political types, such as bystanders and devout and diverse, do not. Yet, there is a notable difference in the recommendation behavior for left-leaning versus right-leaning users. In the first panel, the right-leaning users ultimately exhibit higher clickthrough rates, and more extreme partisan scores, than left-leaning users. Furthermore, this difference is only seen in the content recommender, not for collaborative filtering or oracle recommenders. This is partly due to the asymmetry in the textual similarities between documents of different partisan scores: articles with score 0 are more similar to left-leaning articles (scores -2, -1) than they are to right-leaning articles (scores +1, +2), implying that the content-based recommender has a more difficult time distinguishing between -2 and 0 articles than it does distinguishing between +2 and 0 articles (provided)


